Introduction
Object-oriented handling of audio signals, with fast augmentation routines, batching, padding, and more.
import torch
import audiotools
from audiotools import AudioSignal
from audiotools import post
import rich
import matplotlib.pyplot as plt
import markdown2 as md
from IPython.display import HTML
audiotools.core.playback.DEFAULT_EXTENSION = ".mp3"
state = audiotools.util.random_state(0)
spk = AudioSignal("../tests/audio/spk/f10_script4_produced.wav", offset=5, duration=5)
ir = AudioSignal("../tests/audio/ir/h179_Bar_1txts.wav")
nz = AudioSignal("../tests/audio/nz/f5_script2_ipad_balcony1_room_tone.wav")
Playback and visualization
Let’s first listen to the clean file, and visualize it:
spk.specshow()
plt.show()
spk.embed(display=False)
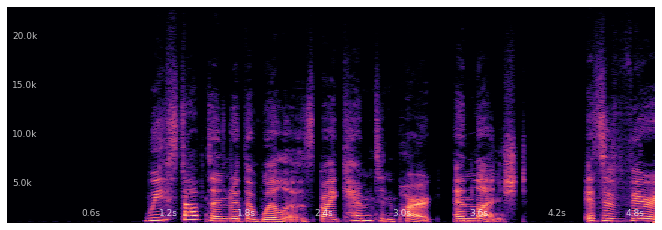
We can also combine the above into a single widget, like so:
spk.widget()
Mixing signals
Let’s mix the speaker with noise at varying SNRs. We’ll make a deep copy
before each mix, to preserve the original signal in spk, as the mix function
is applied in-place.
outputs = {}
for snr in [0, 10, 20]:
output = spk.clone().mix(nz, snr=snr)
outputs[f"snr={snr}"] = output
post.disp(outputs)
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
| . | Audio |
|---|---|
| snr=0 | |
| snr=10 | |
| snr=20 |
Batching signals
We can collate a batch together at random offsets from one file, with the same duration:
batch_size = 16
spk_batch = AudioSignal.batch([
AudioSignal.excerpt('../tests/audio/spk/f10_script4_produced.wav', duration=2, state=state)
for _ in range(batch_size)
])
HTML(md.markdown(spk_batch.markdown(), extras=["tables"]))
| Key | Value |
|---|---|
| duration | 2.000 seconds |
| batch_size | 16 |
| path | ['../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav', '../tests/audio/spk/f10script4produced.wav'] |
| sample_rate | 44100 |
| num_channels | 1 |
| audio_data.shape | torch.Size([16, 1, 88200]) |
| stft_params | STFTParams(windowlength=2048, hoplength=512, windowtype='sqrthann', matchstride=False, paddingtype='reflect') |
| device | cpu |
We can listen to different items in the batch:
outputs = {}
for idx in [0, 2, 5]:
output = spk_batch[idx]
outputs[f"batch_idx={idx}"] = output
post.disp(outputs)
| . | Audio |
|---|---|
| batch_idx=0 | |
| batch_idx=2 | |
| batch_idx=5 |
We can mix each item in the batch at a different SNR:
tgt_snr = torch.linspace(-10, 10, batch_size)
spk_plus_nz_batch = spk_batch.clone().mix(nz, snr=tgt_snr)
Let’s listen to the first and last item in the output:
outputs = {}
for idx in [0, -1]:
output = spk_plus_nz_batch[idx]
outputs[f"batch_idx={idx}"] = output
post.disp(outputs)
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
| . | Audio |
|---|---|
| batch_idx=0 | |
| batch_idx=-1 |
The first item was mixed at -10 dB SNR, and the last at 10 dB SNR.
Perceptual loudness
In Descript, we auto-level to -24dB. Now, we can do the same thing for a batch of audio signals by using an implementation of the same LUFS algorithm used in FFMPEG. This implementation is fully differentiable, and so can be computed on the GPU. Let’s see the loudness of each item in our batch.
print(spk_batch.loudness())
tensor([-16.8203, -17.3237, -17.6142, -18.0535, -16.0414, -17.0968, -16.9068,
-15.4699, -17.3982, -17.3567, -18.2547, -16.3132, -18.9090, -19.0780,
-17.4098, -14.4892])
Now, let’s auto-level each item in the batch to -24 dB LUFS.
output = spk_batch.clone().normalize(-24)
print(output.loudness())
tensor([-24.0000, -24.0000, -24.0000, -24.0000, -24.0000, -24.0000, -24.0000,
-24.0000, -24.0000, -24.0000, -24.0000, -24.0000, -24.0000, -24.0000,
-24.0000, -24.0000])
Let’s make sure the SNR based mixing we did before was actually correct.
print(spk_batch.loudness() - nz.loudness())
print(tgt_snr)
tensor([-10.0000, -8.6667, -7.3333, -6.0000, -4.6667, -3.3333, -2.0000,
-0.6667, 0.6667, 2.0000, 3.3333, 4.6667, 6.0000, 7.3333,
8.6667, 10.0000])
tensor([-10.0000, -8.6667, -7.3333, -6.0000, -4.6667, -3.3333, -2.0000,
-0.6667, 0.6667, 2.0000, 3.3333, 4.6667, 6.0000, 7.3333,
8.6667, 10.0000])
Fairly close.
Convolution
Next, let’s convolve our speaker with an impulse response, to make it sound like they’re in a room.
convolved = spk.clone().convolve(ir)
post.disp(convolved)
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
We can convolve every item in the batch with this impulse response.
spk_batch.clone().convolve(ir)
<audiotools.core.audio_signal.AudioSignal at 0x7ff55201df10>
Or if we have a batch of impulse responses, we can convolve a batch of speech signals with the batch of impulse responses.
ir_batch = AudioSignal.batch([
AudioSignal('../tests/audio/ir/h179_Bar_1txts.wav')
for _ in range(batch_size)
])
spk_batch.clone().convolve(ir_batch)
<audiotools.core.audio_signal.AudioSignal at 0x7ff5522b7250>
There’s also some syntactic sugar for applying convolution.
spk_batch.clone() @ ir_batch # Same as above.
<audiotools.core.audio_signal.AudioSignal at 0x7ff5522a4550>
Equalization
Next, let’s apply some equalization to the impulse response, to simulate different mic responses.
First, we need to figure out the number of bands in the EQ.
n_bands = 6
Then, let’s make a random EQ curve. The curve is in dB.
curve = -2.5 + 1 * torch.rand(n_bands)
Now, apply it to the impulse response.
eq_ir = ir.clone().equalizer(curve)
Then convolve with the signal.
output = spk.clone().convolve(eq_ir)
post.disp(output)
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
Pitch shifting and time stretching
Pitch shifting and time stretching can be applied to signals
outputs = {
"original": spk,
"pitch_shifted": spk.clone().pitch_shift(2),
"time_stretched": spk.clone().time_stretch(0.8),
}
post.disp(outputs)
| . | Audio |
|---|---|
| original | |
| pitch_shifted | |
| time_stretched |
Like other transformations, they also get applied across an entire batch.
spk_batch.clone().pitch_shift(2)
spk_batch.clone().time_stretch(0.8)
<audiotools.core.audio_signal.AudioSignal at 0x7ff590374b20>
Codec transformations
This one is a bit wonky, but you can take audio, and convert it into a a highly compressed format, and then get the samples back out. This creates a sort of “Zoom-y” effect.
output = spk.clone().apply_codec("Ogg")
post.disp(output)
Putting it all together
This is a fluent interface so things can be chained together easily. Let’s augment an entire batch by chaining these effects together. We’ll start from scratch, loading the batch fresh each time to avoid overwriting anything inside the augmentation pipeline.
def load_batch(batch_size, state=None):
spk_batch = AudioSignal.batch([
AudioSignal.salient_excerpt('../tests/audio/spk/f10_script4_produced.wav', duration=5, state=state)
for _ in range(batch_size)
])
nz_batch = AudioSignal.batch([
AudioSignal.excerpt('../tests/audio/nz/f5_script2_ipad_balcony1_room_tone.wav', duration=5, state=state)
for _ in range(batch_size)
])
ir_batch = AudioSignal.batch([
AudioSignal('../tests/audio/ir/h179_Bar_1txts.wav')
for _ in range(batch_size)
])
return spk_batch, nz_batch, ir_batch
We’ll apply the following pipeline, randomly getting parameters for each effect.
Pitch shift
Time stretch
Equalize noise.
Equalize impulse response.
Convolve speech with impulse response.
Mix speech and noise at some random SNR.
batch_size = 4
# Seed is given to function for reproducibility.
def augment(seed):
state = audiotools.util.random_state(seed)
spk_batch, nz_batch, ir_batch = load_batch(batch_size, state)
n_semitones = state.uniform(-2, 2)
factor = state.uniform(0.8, 1.2)
snr = state.uniform(10, 40, batch_size)
# Make a copy so we have it later for training targets.
clean_spk = spk_batch.clone()
spk_batch = (
spk_batch
.pitch_shift(n_semitones)
.time_stretch(factor)
)
# Augment the noise signal with equalization
n_bands = 6
curve = -1 + 1 * state.rand(nz_batch.batch_size, n_bands)
nz_batch = nz_batch.equalizer(curve)
# Augment the impulse response to simulate microphone effects.
n_bands = 6
curve = -1 + 1 * state.rand(ir_batch.batch_size, n_bands)
ir_batch = ir_batch.equalizer(curve)
# Convolve
noisy_spk = (
spk_batch
.convolve(ir_batch)
.mix(nz_batch, snr=snr)
)
return clean_spk, noisy_spk
Let’s augment and then listen to each item in the batch.
clean_spk, noisy_spk = augment(0)
sr = clean_spk.sample_rate
outputs = {}
for i in range(clean_spk.batch_size):
_outputs = {
"clean": clean_spk[i],
"noisy": noisy_spk[i],
}
outputs[f"{i+1}"] = _outputs
post.disp(outputs)
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
/Users/prem/sync/lyrebird-audiotools/audiotools/core/audio_signal.py:523: UserWarning: Audio amplitude > 1 clipped when saving
warnings.warn("Audio amplitude > 1 clipped when saving")
| . | clean | noisy |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 |