Abstract
Long-horizon video generation suffers from two intertwined issues.
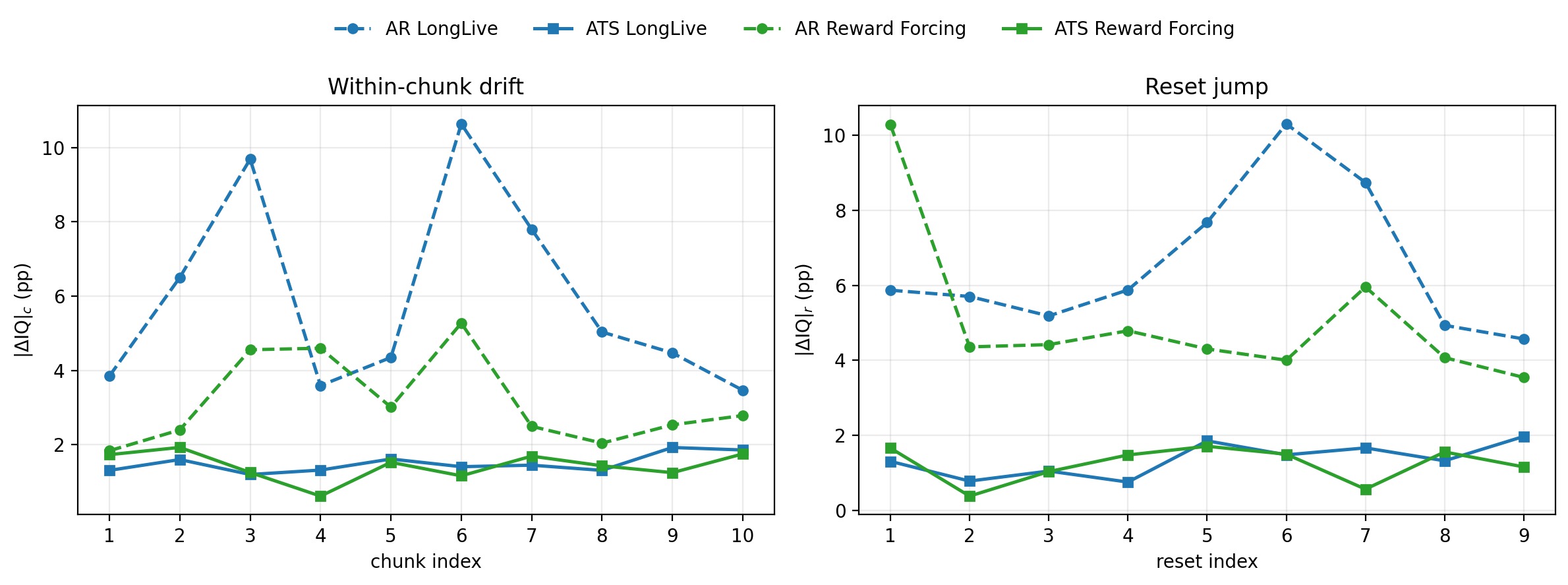
First, there is drift, where video quality degrades over time.
Second, there are continuity issues which manifest as object
permanence failures, or improperly rendering transient content (e.g.,
an object that appears in non-consecutive frames changing color or
style). Recent work has focused on autoregressive distillation
techniques that attack both problems simultaneously.
We instead choose to focus on drift directly and introduce
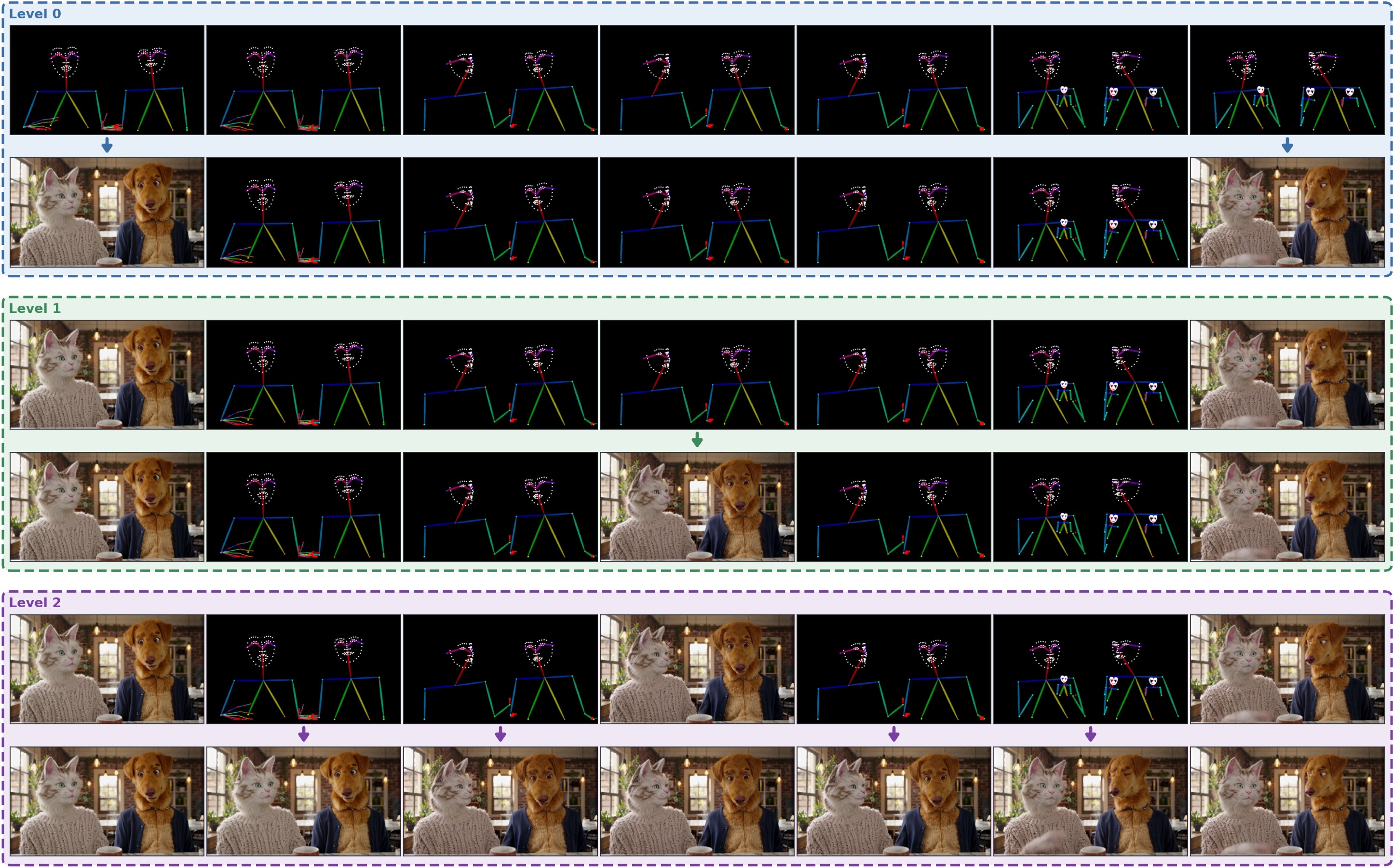
Anchored Tree Sampling (ATS): a training-free,
inference-time scheduler that replaces left-to-right rollout with
sparse-to-dense, anchor-bounded imputation organized as a tree. A root
call produces sparse anchors over the full horizon, recursive
refinement generates intermediate anchors, and final leaf spans are
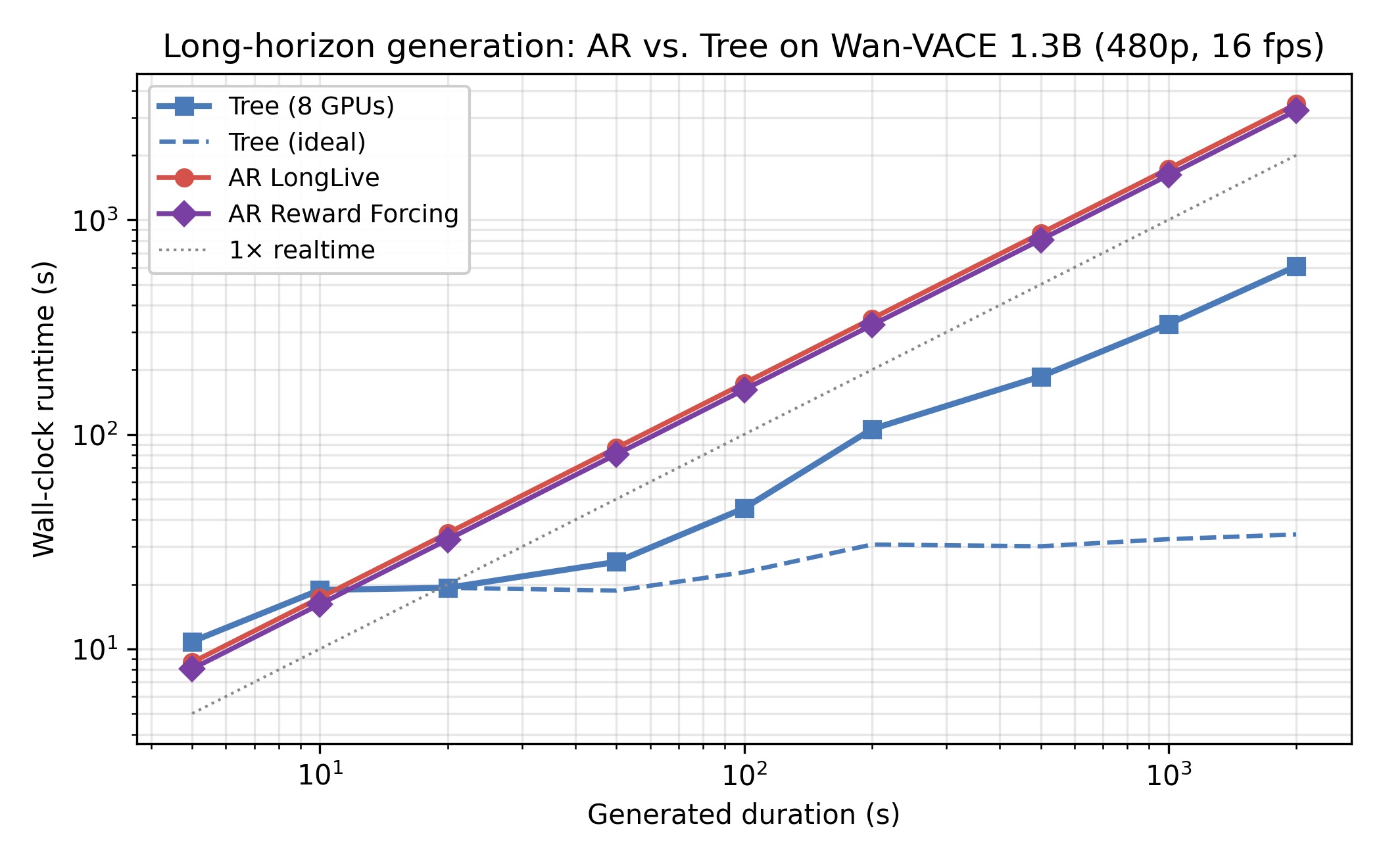
synthesized between neighboring anchors. This reduces the critical
path from K sequential rollout steps to L + 1
tree-hierarchical steps and converts horizon-compounding drift into
anchor-bounded drift.
We focus on V2V generation in the static-camera regime, where
sparse anchors over the horizon are well approximated by the dense
conditioning signal, and the base model can produce them without
retraining. We evaluate ATS against two contemporary autoregressive
baselines on Wan 2.1 + VACE, across five conditioning
modalities (inpainting, outpainting, edge, pose, depth). We show that
ATS outperforms both competitors in overall quality, as well as in
drift prevention. We additionally demonstrate stable
≥ 40-minute generation on LTX-2.3 across the same five
modalities. We conclude by proposing a path forward to extend ATS to
arbitrarily long T2V generation, as well as the dynamic-camera and
multi-shot regimes.